Floating-Point Formats and Deep Learning
Floating-point formats are not the most glamorous or (frankly) the important consideration when working with deep learning models: if your model isn’t working well, then your floating-point format certainly isn’t going to save you! However, past a certain point of model complexity/model size/training time, your choice of floating-point format can have a significant impact on your model training times and even performance.
Here’s how the rest of this post is structured:
- Why should you, a deep learning practitioner, care about what floating-point format your model uses?
- What even is floating-point, especially these new floating-point formats made specifically for deep learning?
- What practical advice is there on using floating-point formats for deep learning?
Floating-Point? In My Deep Learning?
It’s more likely than you think!
It’s been known for quite some time that deep neural networks can tolerate lower numerical precision. High-precision calculations turn out not to be that useful in training or inferencing neural networks: the additional precision confers no benefit while being slower and less memory-efficient.
Surprisingly, some models can even reach a higher accuracy with lower precision, which recent research attributes to the regularization effects from the lower precision.
Finally (and this is speculation on my part — I haven’t seen any experiments or papers corroborating this), it’s possible that certain complicated models cannot converge unless you use an appropriately precise format. There’s a drift between the analytical gradient update and what the actual backward propagation looks like: the lower the precision, the bigger the drift. I’d expect that deep learning is particularly susceptible to an issue here because there’s a lot of multiplications, divisions and reduction operations.
Floating-Point Formats
Let’s take a quick look at three floating-point formats for deep learning. There are a lot more floating-point formats, but only a few have gained traction: floating-point formats require the appropriate hardware and firmware support, which restricts the introduction and adoption of new formats.
For a quick overview, Grigory Sapunov wrote a great run-down of various floating-point formats for deep learning.
IEEE floating-point formats
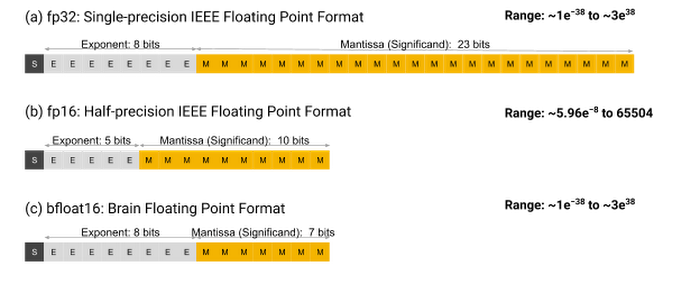
These floating-point formats are probably what most people think of when someone says “floating-point”. The IEEE standard 754 sets out several formats, but for the purposes of deep learning we are only interested three: FP16, FP32 and FP64 (a.k.a. half-, single- and double-precision floating-point formats)1.
Let’s take FP32 as an example. Each FP32 number is a sequence of 32 bits, $b_{31} b_{30} … b_{0}$. Altogether, this sequence represents the real number
$$ (-1)^{b_{31}} \cdot 2^{(b_{30} b_{29} … b_{23}) - 127} \cdot (1.b_{22} b_{21} … b_{0})_2 $$
Here, $b_{31}$ (the sign bit) determines the sign of the represented value.
$b_{30}$ through $b_{23}$ determine the magnitude or scale of the represented value (notice that a change in any of these bits drastically changes the size of the represented value). These bits are called the exponent or scale bits.
Finally, $b_{22}$ through $b_{0}$ determine the precise value of the represented value. These bits are called the mantissa or precision bits.
Obviously, the more bits you have, the more you can do. Here’s how the three formats break down:
| Sign Bits | Exponent (Scale) Bits | Mantissa (Precision) Bits | |
|---|---|---|---|
| FP16 | 1 | 5 | 10 |
| FP32 | 1 | 8 | 23 |
| FP64 | 1 | 11 | 53 |
There are some details that I’m leaving out here (e.g. how to represent NaNs, positive and negative infinities), but this is largely how floating point numbers work. A lot more detail can be found on the Wikipedia page and of course the latest revision of the IEEE standard 754 itself.
FP32 and FP64 are widely supported by both software (C/C++, PyTorch, TensorFlow) and hardware (x86 CPUs and most NVIDIA/AMD GPUs).
FP16, on the other hand, is not as widely supported in software (you need to use a
special library to use them in C/C++). However, since
deep learning is trending towards favoring FP16 over FP32, it has found support in the
main deep learning frameworks (e.g. tf.float16 and torch.float16). In terms of
hardware, FP16 is not supported in x86 CPUs as a distinct type, but is well-supported on
modern GPUs.
Google BFloat16
BFloat16 (a.k.a. the Brain Floating-Point Format, after Google Brain) is basically the same as FP16, but 3 mantissa bits become exponent bits (i.e. bfloat16 trades 3 bits' worth of precision for scale).
When it comes to deep learning, there are generally three “flavors” of values: weights, activations and gradients. Google suggests storing weights and gradients in FP32, and storing activations in bfloat16. However, in particularly gracious circumstances, weights can be stored in bfloat16 without a significant performance degradation.
You can read a lot more on the Google Cloud blog, and this paper by Intel and Facebook studying the bfloat16 format.
In terms of software support, bfloat16 is not supported in C/C++, but is supported in
TensorFlow (tf.bfloat16) and
PyTorch (torch.bfloat16).
In terms of hardware support, it is supported by some modern CPUS, but the real support comes out in GPUs and ASICs. At the time of writing, bfloat16 is supported by the NVIDIA A100 (the first GPU to support it!), and will be supported in future AMD GPUs. And of course, it is supported by Google TPU v2/v3.
NVIDIA TensorFloat
Strictly speaking, this isn’t really its own floating-point format, just an overzealous branding of the technique that NVIDIA developed to train in mixed precision on their Tensor Core hardware2.
An NVIDIA TensorFloat (a.k.a. TF32) is just a 32-bit float that drops 13 precision bits in order to execute on Tensor Cores. Thus, it has the precision of FP16 (10 bits), with the range of FP32 (8 bits). However, if you’re not using Tensor Cores, it’s just a 32-bit float; if you’re only thinking about storage, it’s just a 32-bit float.
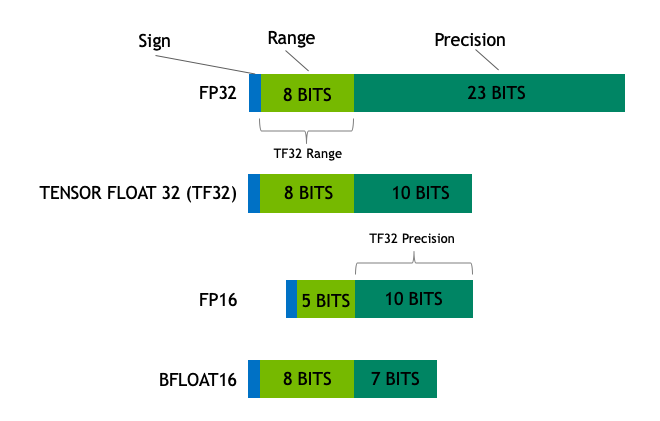
One distinct advantage of TF32 is that they’re kind of like FP32. To quote from the NVIDIA developer blog,
Applications using NVIDIA libraries enable users to harness the benefits of TF32 with no code change required. TF32 Tensor Cores operate on FP32 inputs and produce results in FP32. Non-matrix operations continue to use FP32.
You can read more about TF32 on the NVIDIA blog, and about its hardware support in the Ampere architecture on the NVIDIA developer blog.
TF32 is not in the C/C++ standard at all, but is supported in CUDA 11.
Hardware-wise, the NVIDIA A100 is the first GPU (and, at the time of writing, the only device) supporting TF32.
Advice for Practitioners
The first thing to say is that floating-point formats are by no means the most important consideration for your deep learning model — not even close. Floating-point formats will most likely only make a difference for very large or complex models, for which fitting the model on GPU memory is a challenge, or for which training times are excruciatingly long.
The second thing to say is that any practical advice has to be heavily dependent on what hardware you have available to you.
Automatic mixed precision (AMP) training — a good default
Most deep learning stacks support mixed-precision training, which is a pretty good default option to reap some of the benefits of low-precision training, while still reasonably avoiding underflow and overflow problems.
TensorFlow supports mixed-precision training natively, whereas the NVIDIA Apex library makes automatic mixed precision training available in PyTorch. To get started, take a look at NVIDIA’s developer guide for AMP, and documentation for training in mixed precision.
It’s worth going over the gist of mixed precision training. There are basically two main tricks:
- Loss scaling: multiply the loss by some large number, and divide the gradient updates by this same large number. This avoids the loss underflowing (i.e. clamping to zero because of the finite precision) in FP16, while still maintaining faithful backward propagation.
- FP32 master copy of weights: store the weights themselves in FP32, but cast them to FP16 before doing the forward and backward propagation (to reap the performance benefits). During the weight update, the FP16 gradients are cast to FP32 to update the master copy.
You can read more about these techniques in this paper by NVIDIA and Baidu Research, or on the accompanying blog post by NVIDIA.
Alternative floating-point formats — make sure it’ll be worth it
If you’ve already trained your model in mixed precision, it might not be worth the time or effort to port your code to take advantage of an alternative floating-point format and bleeding edge hardware.
However, if you choose to go that route, make sure your use case really demands it. Perhaps you can’t scale up your model without using bfloat16, or you really need to cut down on training times.
Unfortunately, I don’t have a well-informed opinion on how bfloat16 stacks up against TF32, so “do your homework” is all I can advise. However, since the NVIDIA A100s only just (at the time of writing) dropped into the market, it’ll be interesting to see what the machine learning community thinks of the various low precision options available.
Technically speaking, there are quadruple- and octuple-precision floating-point formats, but those are pretty rarely used, and certainly unheard of in deep learning. ↩︎
A Tensor Core is essentially a mixed-precision FP16/FP32 core, which NVIDIA has optimized for deep learning applications. ↩︎