Transformers in Natural Language Processing — A Brief Survey
I’ve recently had to learn a lot about natural language processing (NLP), specifically Transformer-based NLP models.
Similar to my previous blog post on deep autoregressive models, this blog post is a write-up of my reading and research: I assume basic familiarity with deep learning, and aim to highlight general trends in deep NLP, instead of commenting on individual architectures or systems.
As a disclaimer, this post is by no means exhaustive and is biased towards Transformer-based models, which seem to be the dominant breed of NLP systems (at least, at the time of writing).
Some Architectures and Developments
Here’s an (obviously) abbreviated history of Transformer-based models in NLP1 in (roughly) chronological order. I also cover some other non-Transformer-based models, because I think they illuminate the history of NLP.
word2vec and GloVe
These were the first instances of word embeddings pre-trained on large amounts of unlabeled text. These word embeddings generalized well to most other tasks (even with limited amounts of labeled data), and usually led to appreciable improvements in performance.
These ideas were immensely influential and have served NLP extraordinarily well. However, they suffer from a major limitation. They are shallow representations that can only be used in the first layer of any network: the remainder of the network must still be trained from scratch.
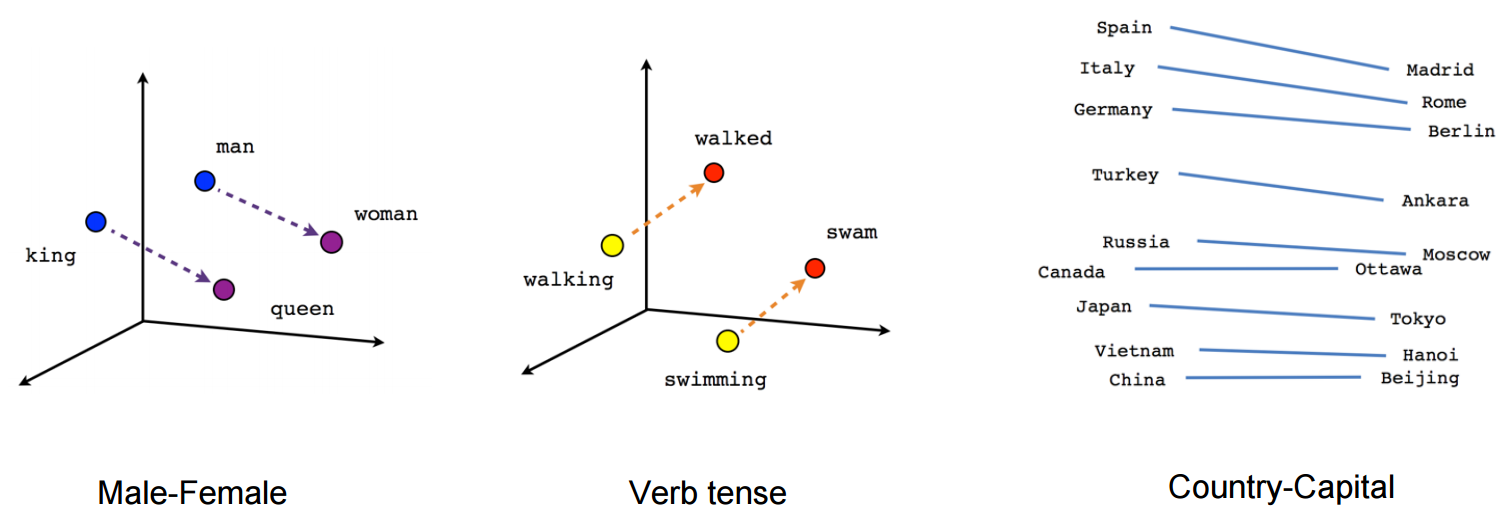
The main appeal is well illustrated below: each word has its own vector representation, and there are linear vector relationships can encode common-sense semantic meanings of words.
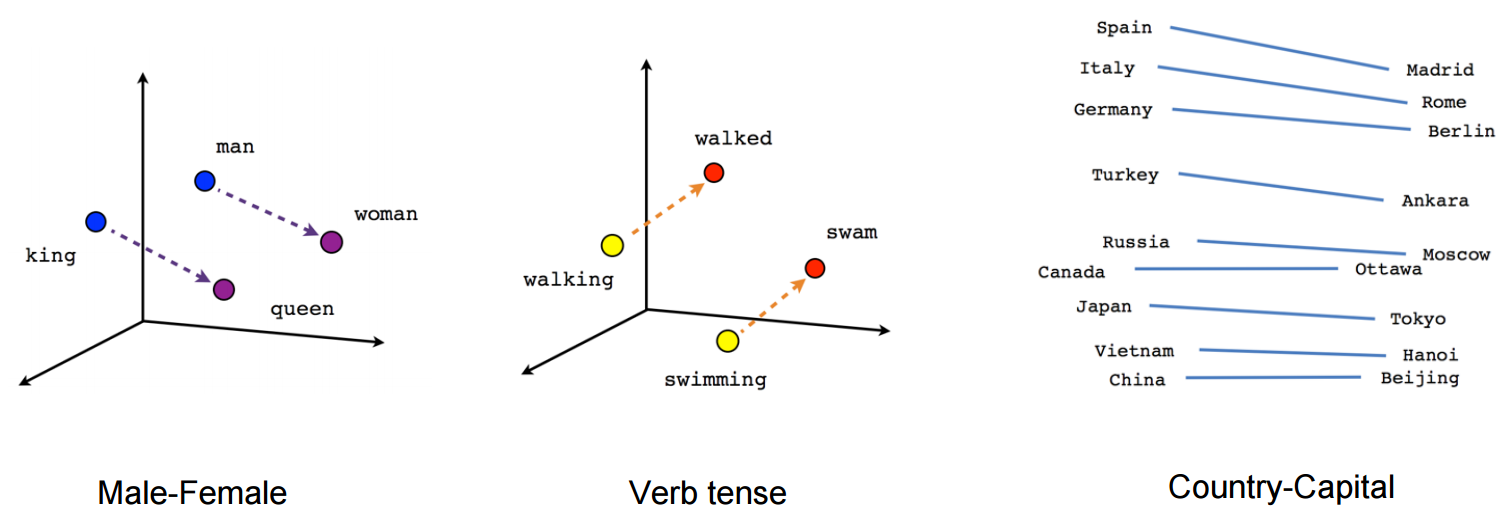
Linear vector relationships in word embeddings. Source: TensorFlow documentation. Further reading
Broadly speaking, after word2vec/GloVe and before Transformers, a lot of ink was spilled on other different approaches to NLP, including (but certainly not limited to)
- Convolutional neural networks
- Recurrent neural networks
- Reinforcement learning approaches
- Memory-augmented deep learning
- Perhaps the most famous of such models is ELMo (Embeddings from Language Models) by AI2, which learned bidirectional word embeddings using LSTMs, and began NLP’s fondness of Sesame Street.
- I won’t go into much more detail here: partly because not all of these approaches have held up as well as current Transformer-based models, and partly because I have plans for my computer that don’t involve blogging about recent advances in NLP.
- Here is a survey paper (and an associated blog post) published shortly after the Transformer was invented, which summarizes a lot of the work that was being done during this period.
Transformer
The authors introduce a feed-forward network architecture, using only attention mechanisms and dispensing with convolutions and recurrence entirely (which were not uncommon techniques in NLP at the time).
It achieved state-of-the-art performance on several tasks, and (perhaps more importantly) was found to generalize very well to other NLP tasks, even with limited data.
Since this architecture was the progenitor of so many other NLP models, it’s worthwhile to dig into the details a bit. The architecture is illustrated below: note that its feed-forward nature and multi-head self attention are critical aspects of this architecture!
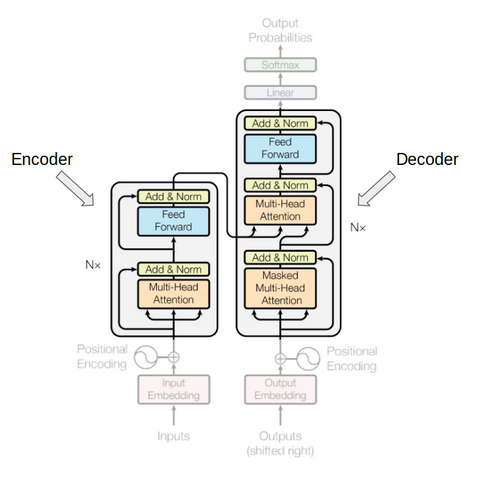
Graphical representation of BERT. Source: Pinterest. Further reading
ULMFiT (Universal Language Model Fine-tuning for Text Classification)
- The authors introduce an effective transfer learning method that can be applied to any task in NLP: this paper introduced the idea of general-domain, unsupervised pre-training, followed by task-specific fine-tuning. They also introduce other techniques that are fairly common in NLP now, such as slanted triangular learning rate schedules. (what some researchers now call warm-up).
- Further reading
GPT-1 and GPT-2 (Generative Pre-trained Transformers)
- At the risk of peeking ahead, GPT is largely BERT but with Transformer decoder blocks, instead of encoder blocks. Note that in doing this, we lose the autoregressive/unidirectional nature of the model.
- Arguably the main contribution of GPT-2 is that it demonstrated the value of training larger Transformer models (a trend that I personally refer to as the Embiggening).
- GPT-2 generated some controversy, as OpenAI initially refused to open-source the model, citing potential malicious uses, but ended up releasing the model later.
- Further reading
BERT (Bidirectional Encoder Representations from Transformers)
The authors use the Transformer encoder (and only the encoder) to pre-train deep bidirectional representations from unlabeled text. This pre-trained BERT model can then be fine-tuned with just one additional output layer to achieve state-of-the-art performance for many NLP tasks, without substantial task-specific architecture changes, as illustrated below.
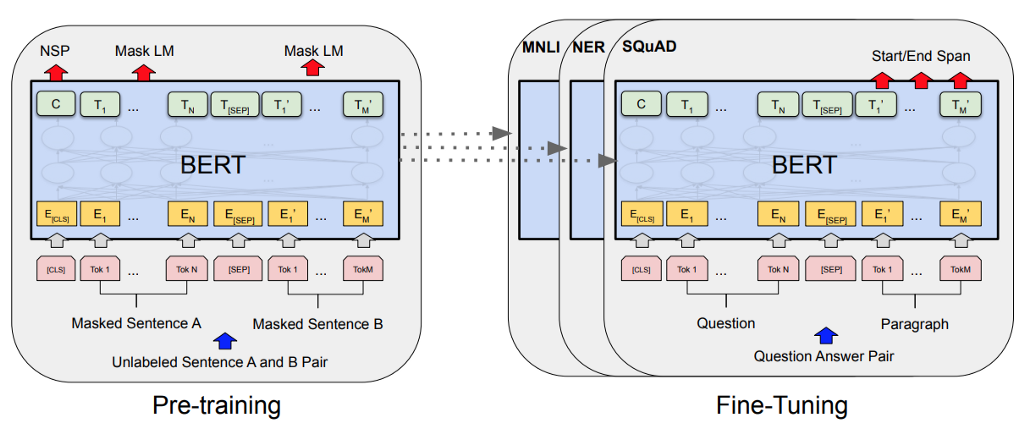
Graphical representation of BERT. Source: Pinterest. BERT was a drastic development in the NLP landscape: it became almost a cliche to conclude that BERT performs “surprisingly well” on whatever task or dataset you throw at it.
Further reading
RoBERTa (Robustly Optimized BERT Approach)
The scientific contributions of this paper are best quoted from its abstract:
We find that BERT was significantly under-trained, and can match or exceed the performance of every model published after it. […] These results highlight the importance of previously overlooked design choices, and raise questions about the source of recently reported improvements.
The authors use an identical architecture to BERT, but propose several improvements to the training routine, such as changing the dataset and removing the next-sentence-prediction (NSP) pre-training task. Funnily enough, far and away the best thing the authors did to improve BERT was just the most obvious thing: train BERT for longer!
Further reading:
T5 (Text-to-Text Transfer Transformer)
- There are two main contributions of this paper:
- The authors recast all NLP tasks into a text-to-text format: for example, instead of performing a two-way softmax for binary classification, one could simply teach an NLP model to output the tokens “spam” or “ham”. This provides a unified text-to-text format for all NLP tasks.
- The authors systematically study and compare the effects of pre-training objectives, architectures, unlabeled datasets, transfer approaches, and other factors on dozens of canonical NLP tasks.
- This paper (and especially the tables in the appendices!) probably cost the Google team an incredible amount of money, and the authors were very thorough in ablating what does and doesn’t help for a good NLP system.
- Further reading
- There are two main contributions of this paper:
{kind=link}
{kind=link}
Some Thoughts and Observations
Here I comment on some general trends that I see in Transformer-based models in NLP.
Ever since Google developed the Transformer in 2017, most NLP contributions are not architectural: instead most recent advances have used the Transformer model as-is, or using some subset of the Transformer (e.g. BERT and GPT use exclusively Transformer encoder and decoder blocks, respectively). Instead, recent research has focused on the way NLP models are pre-trained or fine-tuned, or creating a new dataset, or formulating a new NLP task to measure “language understanding”, etc.
- I’m personally not sure what to make of this development: why did we collectively agree that architectural research wasn’t worth pursuing anymore?
- But spinning this the other way, we see that Transformers are a fascinating architecture: the model has proven so surprisingly versatile and easy to teach that we are still making meaningful advances with the same architecture. In fact, it is still an open question how and why Transformers perform as well as they do: there is an open field of research focusing on answering this question for BERT (since BERT has been uniquely successful model) called BERTology.
It was never a question of whether NLP systems would follow computer vision’s model of fine-tuning pre-trained models (i.e. training a model on ImageNet and then doing task-specific fine-tuning for downstream applications), but rather how.
- What specific task and/or dataset should NLP models be pre-trained on?
- Language modelling has really won out here: BERT was originally published with a next-sentence prediction (NSP) pre-training task, which RoBERTa completely did away with.
- Exactly what is being learnt during pre-training?
- Initially it was a separate vector for each token (i.e. pre-training a shallow representation of text), and these days it is an entire network is pre-trained.
- Sebastian Ruder wrote a great article that delves more into this topic.
- What specific task and/or dataset should NLP models be pre-trained on?
There are (generally speaking) three flavors of Transformer models.
- Autoregressive models
- Autoencoding models
- Sequence-to-sequence models
- Hugging Face does an excellent job of summarizing the differences between these three flavors of models in their Summary of the Models, which I’ve reproduced here:
Autoregressive models are pretrained on the classic language modeling task: guess the next token having read all the previous ones. They correspond to the decoder of the original transformer model, and a mask is used on top of the full sentence so that the attention heads can only see what was before in the next, and not what’s after. Although those models can be fine-tuned and achieve great results on many tasks, the most natural application is text generation. A typical example of such models is GPT.
Autoencoding models are pretrained by corrupting the input tokens in some way and trying to reconstruct the original sentence. They correspond to the encoder of the original transformer model in the sense that they get access to the full inputs without any mask. Those models usually build a bidirectional representation of the whole sentence. They can be fine-tuned and achieve great results on many tasks such as text generation, but their most natural application is sentence classification or token classification. A typical example of such models is BERT.
[…]
Sequence-to-sequence models use both the encoder and the decoder of the original transformer, either for translation tasks or by transforming other tasks to sequence-to-sequence problems. They can be fine-tuned to many tasks but their most natural applications are translation, summarization and question answering. The original transformer model is an example of such a model (only for translation), T5 is an example that can be fine-tuned on other tasks.
Different NLP models learn different kinds of embeddings, and it’s worth understanding the differences between these various learnt representations.
- Contextual vs non-contextual embeddings
- The first word embeddings (that is, word2vec and GloVe) were non-contextual: each word had its own embedding, independent of the words that came before or after it.
- Almost all other embeddings are contextual now: when embedding a token, they also consider the tokens before &/ after it.
- Unidirectional vs bidirectional embeddings
- When considering the context of a token, the question is whether you should consider the tokens both before and after it (i.e. bidirectional embeddings), or just the tokens that came before (i.e. unidirectional embeddings).
- Unidirectional embeddings make the sense when generating text (i.e. text generation must be done in the way humans write text: in one direction). On the other hand, bidirectional embeddings make sense when performing sentence-level tasks such as summarization or rewriting.
- The Transformer was notable in that it had bidirectional encoder blocks and unidirectional decoder blocks. That’s why BERT [GPT-2] produces bidirectional [unidirectional] embeddings, since it’s a stack of Transformer encoders [decoders].
- Note that the unidirectional/bidirectional distinction is related to whether or not the model is autoregressive: autoregressive models learn unidirectional embeddings.
- Contextual vs non-contextual embeddings
Transformer-based models have had an interesting history with scaling.
- This trend probably started when GPT-2 was published: “it sounds very dumb and too easy, but magical things happen if you make your Transformer model bigger”.
- An open question is, how do Transformer models scale (along any dimension of interest)? For example, how much does dataset size or the number of layers or the number of training iterations matter in the ultimate performance of a Transformer model? At what point does making your Transformer model “bigger” (along any dimension of interest) provide diminishing returns?
- There is some solid work being done to answer this question, and there seems to be good evidence for some fairly surprising conclusions!
#Machine-Learning #Deep Learning #Natural-Language-Processing